
Wie strukturiert man ein Akquisitionssystem unabhängig von Algorithmen? Ingenieurs- und Softwareteams setzen zunehmend auf Architekturprinzipien, die Datenaufnahme und Verarbeitung so entkoppeln, dass Analyse- oder Lernalgorithmen später beliebig ausgetauscht werden können. Dieser Artikel fasst etablierte Ansätze aus Industrie und Forschung zusammen, nennt relevante Standards und zeigt praktische Konsequenzen für die Systemarchitektur in Produktions‑ und IoT‑Umgebungen.
Wer: Hersteller, Integratoren und Standards‑Organisationen; Was: Konzepte zur Strukturierung von Akquisitionssystemen; Wann/Warum: angesichts wachsender Datenmengen und heterogener Analytik zunehmend relevant; Wo: Industrieautomation, Automotive, verteilte IoT‑Netze.
Akquisitionssystem entkoppeln: Architekturprinzipien für unabhängige Algorithmen
Die Kernidee besteht darin, die Systemarchitektur so zu gestalten, dass Sensorik, Signalaufbereitung und Algorithmen getrennte Schichten bilden. Das reduziert die Kopplung und erhöht die Flexibilität bei der Einführung neuer Auswertungsverfahren.
Problem, Lösung und Beispiele aus der Praxis
Problem: Direkt in Sensorfirmware integrierte Algorithmen erschweren Updates und Vergleichbarkeit. Lösung: Eine klare Trennung durch standardisierte Schnittstellen (z. B. OPC UA, MQTT) und einheitliche Zeitstempel erlaubt, Rohdaten unverändert zu speichern und hinterher verschiedene Verfahren anzuwenden.
Beispiele: Messtechnikhersteller wie National Instruments und Plattformanbieter im Industrial‑IoT empfehlen modulare Datenschichten; Time‑Series‑Datenbanken wie InfluxDB oder TimescaleDB dienen dabei als persistente Schicht für spätere Analysen.
Insight: Eine robuste Trennung verbessert Wartbarkeit und macht das Akquisitionssystem algorithmisch unabhängig.
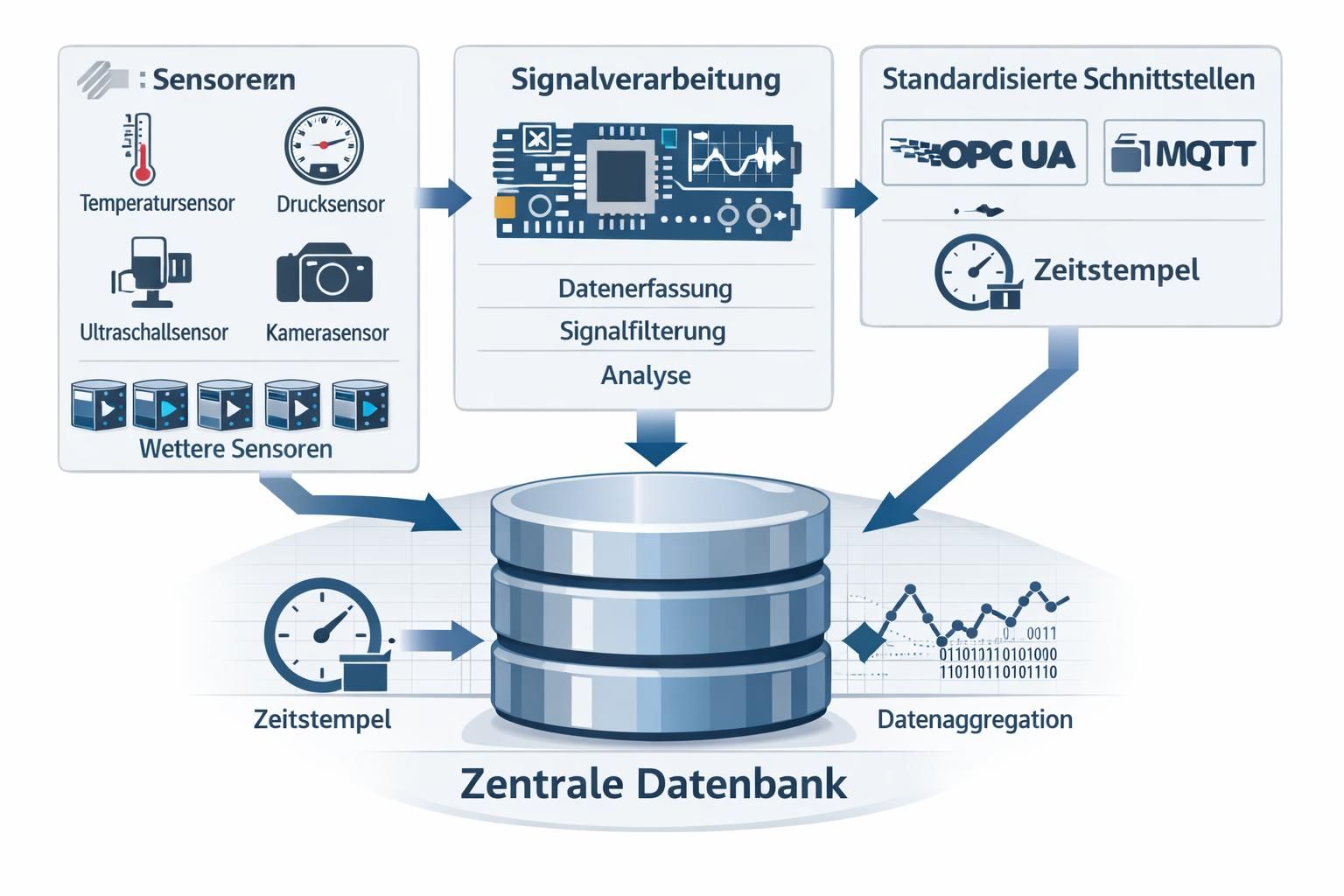
Signalverarbeitung und Datenaufnahme: technische Grundlagen für unabhängige Verarbeitung
Die Qualität der Datenaufnahme entscheidet, welche Algorithmen später sinnvoll anwendbar sind. Klassische Regeln der Signalverarbeitung bleiben zentral: Abtastrate nach dem Nyquist‑Shannon‑Prinzip, Anti‑Aliasing‑Filter und präzise Zeitstempel.
Konkrete Maßnahmen und ihre Auswirkungen
Maßnahmen wie deterministische Sampling‑Pipelines, deterministische Latenzpuffer und Metadaten‑Erfassung (Kamera‑Exposure, Sensor‑Kalibrierung) sorgen dafür, dass verschiedene Auswertungen vergleichbar bleiben. Das Prinzip von in‑place versus out‑of‑place Verarbeitung hilft abzuwägen, ob Zwischenspeicher lokal oder in zentralen Speichern gehalten werden.
Folge: Bessere Reproduzierbarkeit von Ergebnissen und schnellere Abläufe beim Austausch von Klassifikatoren oder Sortier‑/Filteralgorithmen.
Insight: Sorgfältige Signalverarbeitung macht den späteren Algorithmuswechsel möglich, ohne die Rohdatensammlung zu verändern.
Modularität, Datenintegration und Governance: Ökosysteme für algorithmusunabhängige Systeme
Eine modulare Plattformarchitektur fördert Modularität und erleichtert Datenintegration über heterogene Quellen. Offene Formate (z. B. Parquet, JSON‑L, Protobuf) und standardisierte APIs bilden die Basis für interoperable Pipelines.
Institutionen, Plattformen und wirtschaftliche Effekte
Standards wie die vom OPC Foundation und OASIS‑gepflegte Protokolle sind weit verbreitet. Cloud‑ und Edge‑Anbieter (Azure IoT, AWS IoT Edge) bieten mittlerweile Referenzarchitekturen, die lokale Vorverarbeitung mit zentraler Speicherung kombinieren.
Wirtschaftlich bedeutet das: schnellere Integration neuer Analytik, geringere Risiken bei Technologieaustausch und niedrigere Entwicklungskosten durch Wiederverwendbarkeit von Komponenten.
Insight: Governance‑Regeln für Metadaten, Zugriffskontrolle und Datensicherung sind Schlüsselfaktoren, damit ein Akquisitionssystem langfristig algorithmusunabhängig bleibt.







