
Unternehmen nutzen zunehmend Verhaltensdaten, um individuelle Erlebnisse automatisiert auszuliefern. Onlinehändler, Plattformbetreiber und Dienstleister setzen seit 2024/2025 verstärkt auf ereignisgetriebene Datenverarbeitung und Maschinelles Lernen, um Kundenerlebnis und Conversion-Raten in Echtzeit zu verbessern. In Deutschland stehen dabei neben technischen Fragen vor allem DSGVO-konformität und Datenqualität im Fokus.
Verhaltensdatenmodelle für die Automatisierung individueller Erlebnisse
Verhaltensdatenmodelle strukturieren Nutzeraktionen wie Klicks, Käufe oder Session‑Events zeitlich und ereignisbasiert. Typische Ereignisse enthalten Felder wie event_name, timestamp und user_id sowie Metadaten zu Gerät, Produkt oder Referrer. Solche Datenverarbeitung-Pipelines laufen in der Praxis über Technologien wie Kafka Streams, Spark und Delta Lake und ermöglichen auditable, append-only-Protokolle.
Was diese Modelle konkret ermöglichen
Prädiktive Modelle sagen Kaufwahrscheinlichkeiten oder Abwanderungsrisiken voraus; Anomalieerkennung identifiziert untypische Zugriffe zur Stärkung der Cybersicherheit. Ein e‑Commerce-Beispiel: Eine Pipeline, die Nutzeraktivität in Echtzeit verarbeitet, kann den Average Order Value (AOV) gezielt um rund 25 % erhöhen, indem sie verhaltensbasierte Produktempfehlungen ausspielt. Plattformen wie Netflix zeigen, wie Empfehlungsmaschinen Nutzerbindungsraten steigern.
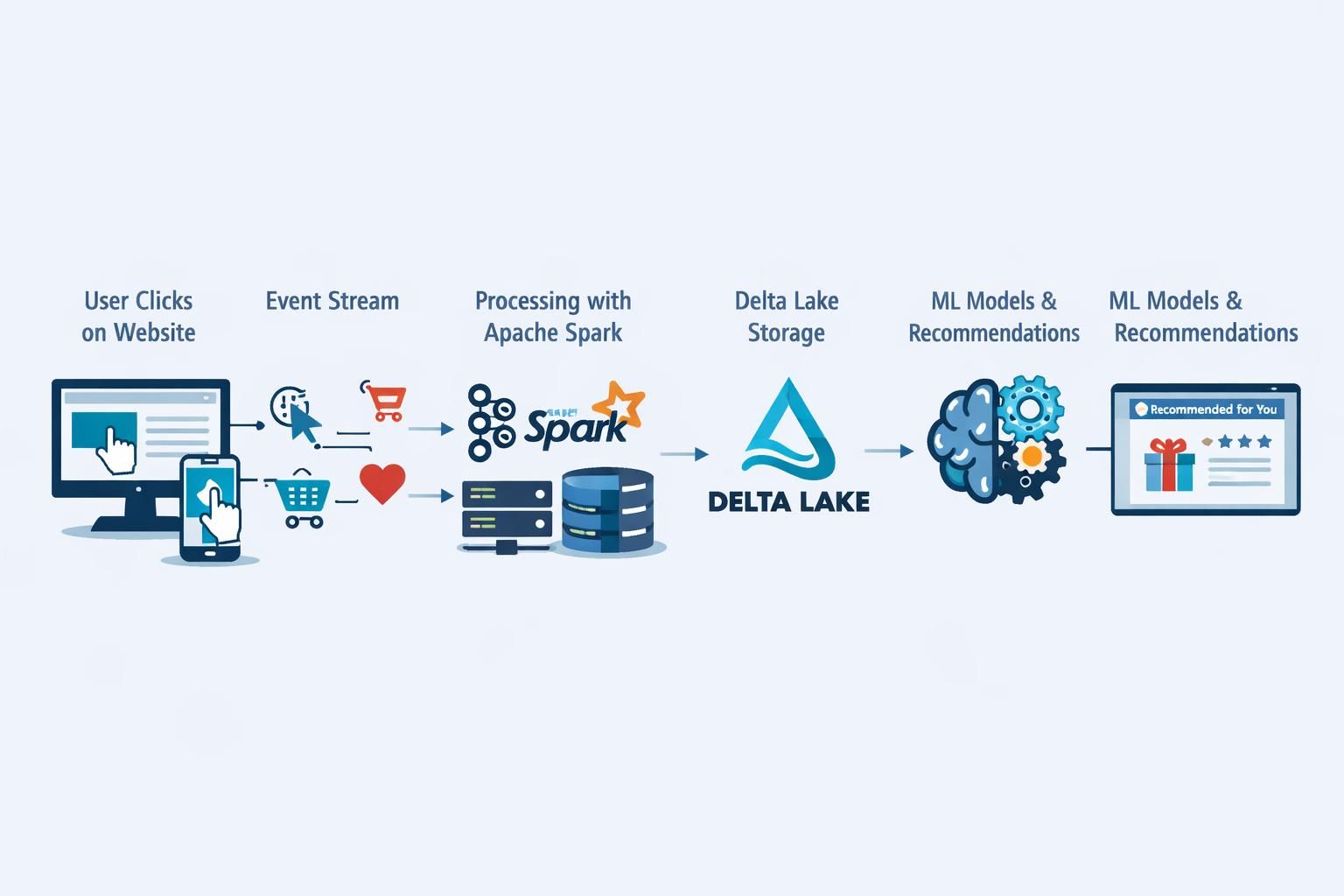
Echtzeit-Anpassung und Maschinelles Lernen für zielgenaue Personalisierung
Echtzeit-Analytik erlaubt Echtzeit-Anpassung von Inhalten innerhalb von Millisekunden. Kombinationen aus Clustering (z. B. K‑Means, hierarchisches Clustering) und prädiktiven Verfahren wie Collaborative Filtering schaffen dynamische Segmente und individualisierte Inhalte.
Methoden und technische Voraussetzungen
Contextual Bandits balancieren Exploration und Exploitation, um Inhalte relevant zu halten. Ensemble‑Ansätze wie Random Forest reduzieren Fehlentscheidungen, während Edge Computing Latenzen auf unter 100 Millisekunden drücken kann. Tools wie Google Analytics 4, Adobe Target oder Optimizely unterstützen die Implementierung von A/B‑Tests und Echtzeit‑Personalisierung.
Datenschutz, Implementierung und Folgen für das Kundenerlebnis
Die rechtliche Grundlage ist zentral: Ohne gültige Einwilligung riskieren Unternehmen Bußgelder von bis zu 20 Mio. € oder 4 % des Jahresumsatzes. Consent‑Management‑Lösungen wie Cookiebot oder OneTrust sind daher in vielen Projekten Pflicht.
Praktische Herausforderungen und Best Practices
Häufige Hürden sind Datensilos und mangelhafte Datenqualität. Interne Zugriffe, Bot‑Traffic und fehlerhafte Sessions können 15–20 % der Rohdaten verfälschen; regelmäßige Audits und Filter sind nötig. Für KMU sind All‑in‑One‑Lösungen eine pragmatische Einstiegsmöglichkeit, während größere Unternehmen auf spezialisierte Data Warehouses wie BigQuery oder Amazon Redshift setzen.
Als praxisnahes Beispiel nutzt der Einzelhändler OTTO verhaltensbasierte Trigger, um bei Warenkorb‑Abbrüchen gezielt Erinnerungen oder Rabatte zu senden. Solche Maßnahmen verbessern das Kundenerlebnis, verlangen jedoch transparente Kommunikation über Datennutzung und einfache Opt‑out‑Möglichkeiten.
Kurzfristig bleibt die Balance zwischen Personalisierung und Datenschutz die zentrale Gestaltungsfrage. Technisch führen Fortschritte in Maschinellem Lernen und Echtzeit‑Infrastruktur zu stärkeren Automatisierungs‑möglichkeiten, regulatorisch ist mit präziseren Vorgaben und mehr Kontrolle durch Nutzer zu rechnen.







